1. 从一线“泥泞”到行业“修路”

之前在光爱学校工作的那五年,我一直处于公益的一线。那时我最直观的感受是:技术应用和数字化,对于很多基层公益机构来说,并不是不重要,而是——有些“顾不上”。
大家每天忙于具体的救助、筹款和各种繁杂事务,很难抽出人手和精力去做数字化建设。
这种技术的“滞后”,不仅让一线工作显得原始而冗余,也让很多真实的辛劳和善意,因为缺乏记录与整理,逐渐消失在公众的视野里。
2024年,我来到基金会中心网工作,身份从一线的实践者,转变为一个面向行业的数据服务者。
虽然我们直接服务的是基金会,但我常常在想:我们把这些数据理顺,对那些还在一线奔波的公益人,究竟意味着什么?
慢慢地,我开始意识到:平台数字化的本质,其实是在做一件“修路”的事情。
只有把全行业散乱的数据分好类、理清楚,让每一个具体的公益项目都能通过标签被精准检索,一线机构的工作,才有可能被更多人看见;当“资助方”和“执行方”之间能够更高效地匹配,资源才更有可能流向真正需要的地方。
这些工作看起来离一线有些距离,但从更宏观的角度来看,无论是行业论坛的组织,还是数据平台的建设,本质上都是在做同一件事——为公益行业提供基础设施支持。
2. 45万个项目背后的“深渊”
目前,基金会中心网已经累计观测了约45万个公益项目。
如果你翻看过各个基金会的年报,就会发现一个非常现实的问题:填报质量极其参差不齐。
有的项目介绍长达几千字,试图讲清所有故事,却抓不住重点;
有的则只有寥寥数语,让人几乎无法判断项目的具体内容。
这种海量且非标准的原始数据,靠人工分类几乎是不可能完成的任务。
但需要说明的是,在基金会年报填报体系中,其实已经存在“服务领域”的分类选项。
基金会在填报项目时,需要为每个项目选择所属的服务领域,这在一定程度上,为项目提供了基础的分类信息。
不过在实际使用中,这套分类体系也存在一些现实边界:
- 不同年度、不同地区的填报口径会有所调整,缺乏长期一致性
- 具体填报人员对项目的理解存在差异,同类项目可能被归入不同领域
- 一些项目本身具有跨领域属性,很难用单一分类准确表达
在这种情况下,“服务领域”更多承担的是填报维度的数据记录功能,而在行业研究与数据分析层面,仍然缺乏一套稳定、统一、可比的分类体系。
这也直接导致一个结果:行业难以基于议题,对项目进行有效的检索与分析。
为了弥补这一缺口,基金会中心网基于长期的数据积累与行业观察,梳理并建立了一套标签体系,涵盖19个一级议题领域分类标签和115个二级分类标签:
19个一级分类标签:
教育发展、医疗健康、生态环境、文化艺术、体育、助弱济困、社会优抚、乡村振兴、社区治理、应急管理、法律支持、科学技术、国际合作与发展、公益行业支持、青少年服务、女性发展、残障、养老支持与服务、以及“其他”。
试图从行业分析的视角出发,为这些分散的数据建立一个相对统一的“坐标系”。
但新的问题随之而来:这45万条项目,如何完成高质量、可规模化的标签分类?
3. 从“人工智能”到“自动驾驶”:三次技术突围
在实际的业务场景中,要让AI乖乖听话且高效工作,需要经历不断的“调教”。以下是我在开发过程中尝试过的三种路径,希望能给同样在探索“技术向善”的朋友一点参考。
方案一:初级智能体(Coze方案)——“心太野”

我最先尝试了目前很火的智能体工具。通过RAG(检索增强生成)能力,希望它能够对照知识库直接打标。
遇到的坑:准确率很不理想。AI经常出现“幻觉”,它会觉得自己比规则更聪明,跳出知识库定义的标签去自创标签。在处理海量数据时,这种哪怕10%的偏差都是灾难性的。
方案二:本地知识库(CherryStudio方案)——“效率瓶颈”

我换了思路,通过向量模型将标签定义转为本地知识库索引,再调用大模型进行匹配。
遇到的坑:准确率提高了,但效率太低。这依然是一种“对话式”思维,如果靠人工复制粘贴项目内容并等待结果,处理完45万次,可能需要好几年。
方案三:Python多线程自动化 + 大模型API——真正的生产力

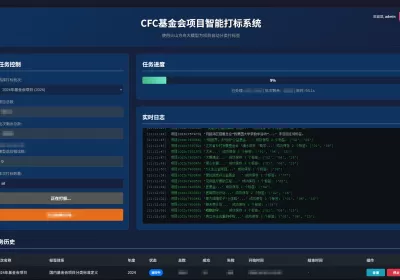
最后,我回归到了程序员的终极武器:代码自动化。利用AI辅助生成的Python脚本,我调用了API接口,搭建了一套自动打标系统。这个方案的打标签结果,即准确又高效。
实现逻辑:它像一个勤恳的流水线工人,我开启了10个线程并行工作。它会自动读取项目名称、描述、基金会信息,调用火山方舟知识库检索,返回打标签结果,实时记录日志并重试失败项。
效果:仅仅用了一天时间,就把整个年度的基金会项目全部分类打标完成。
4. 让每一份善意拥有自己的“坐标”
在公益行业,“看不见”往往意味着无法连接。有了这些分类,这套系统就不再只是代码,而是一个服务于大家的工具:
- 对于捐赠者:你不再需要从茫茫大海里找项目。如果你关注“残障”或“女性发展”,只需一键筛选,就能看到全国有哪些基金会在深耕这个领域,他们的项目做得怎么样。
- 对于求职者:如果你是一个热衷于“生态环境”的年轻人,通过这些标签,你可以迅速锁定这个赛道里所有的基金会,看清他们的项目分布和关联,找到真正志同道合的机构。
- 对于行业研究者:你可以一眼看出哪些领域是“热点”,哪些领域如“法律支持”或“公益行业支持”还需要更多的资源倾斜。
这件事情的本质,其实可以用一句话来概括:让每一份善意,都拥有一个可以被识别和连接的“坐标”。
5. 写在最后的话

现在,如果你打开基金会中心网的官网,已经可以按议题领域去查询项目了。那些曾经沉睡在年报里的文字,开始变成可以被检索、被分析、被使用的数据。
写下这个过程,不只是想分享一段技术探索的路径,更是想传递一个很朴素的感受:在AI时代,公益从业者其实不必被技术门槛所阻挡。
这套系统的大部分代码,也是借助AI辅助完成的。
技术本身并不冷冰冰,关键在于——你希望用它去解决什么问题。

在这 19 个公益领域中,你最关注哪一个?欢迎留言告诉我,我也许能帮你从数据中解读这个领域的现状。